Slotted Pages in Databases
Recently, I’ve been reading Alex Petrov’s as a part of a book club. It has been very insightful into the inner workings of a database. Things that you don’t really think about when it comes to data. How is the system that stores data efficiently organized and what challenges come up in that effort?
What are we storing?
Databases deal with records, from employees of a company to patients at a hospital. There needs to be an efficient way to store these records which abstracts away the disk to memory swaps needed to deal with large data records.
Databases solve this problem. They store each record as tuples, usually having a key that can uniquely identify the tuple (or a key set up by the db itself).
What problems arise?
As it can be seen, handling this complexity won’t come easily. There are a bunch of issues that make the process difficult and need to be dealt with when creating a database. The main three ones are listed.
- Records aren’t always of fixed length. Take a simple address field which can be represented as a string in memory. This field can be very large, demanding special management to reduce the amount of wasted memory space. (memory is expensive!!!!).
- If records are stored sequentially in a file the problem of fragmentation and ordering comes up. Reclaiming space from deleted records requires intensive moving operations.
- Records can’t be directly referenced because of their location in memory changes, for whatever reason, each reference needs to be modified (expensive!!!!).
Solution?
✨ SLOTTED PAGES ✨
This miracle structure allows the database to deal with the problems mentioned before in the best and easy-to-understand way. Each page is split up into three main parts.
- Header: containing metadata and other important cell and page information. (checksum, flags)
- Pointers/Offsets: holds the offsets and size of each cell and maintains logical ordering of cells.
- Cells: the actual tuples of information.
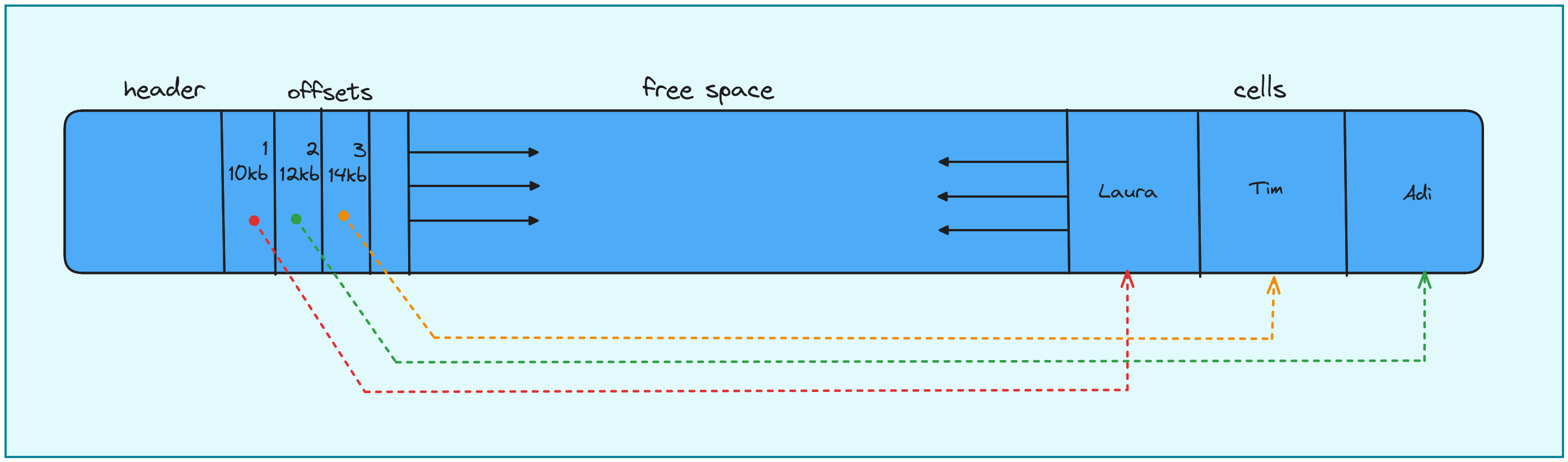
This has some pretty cool, not-so-easy-to-notice features.
- The offsets handle the logical ordering of the cells, from the figure you can see that the order of the cells is Laura -> Adi -> Tim.
- Deleting a record means just marking the offset as invalid, updating means marking the old cell as invalid and adding a new cell. The reclaiming of this space and subsequent defragmentation is done at a later time.
- Defragmentation is a lot easier to handle, the tuples can be moved without the reference (offset) having to be changed.
- The tuples are no longer restricted by size and can have variable-sized fields.
- Each tuple can be referenced by a simple
tuple_index = <page id, offset id>
« Different types of Nuclear Bombs
The V8 Javascript Engine »